推动科学发现客户分析等的可视化技术
人工智能研究所Skoltech和AIRI的研究人员设计了一种可视化技术,使人类可以访问高度复杂的生物医学、金融和其他数据集,而不会牺牲其多维结构。保留这种所谓的数据拓扑对于得出有关癌症基因、消费者行为等的结论至关重要。然而,现有的方法并不擅长。该研究将作为会议论文在ICLR2023上发表,该论文可在arXiv预印本服务器上获得。
公司分析师和科学家通常必须理解数据集,其中每个项目都具有许多所谓的维度特征。例如,一家银行可能会根据广泛的行为指标对其每个客户进行评级。生物学家根据大量基因中每个基因的活跃程度来考虑各种细胞。天气数据也具有这种性质,因为在每个位置的每个时间点报告的参数数量很多。
然而,人们不习惯从多个维度进行思考,如果不将数据集简化为二维或三维表示,可能很难提出有意义的假设并识别重要的模式。
“可视化使数据直观,但不一定能揭示其‘形状’。一个数据集可能有一个大规模的结构——完整的集群、空洞、循环等等——我们希望所有这些都以降维表示,也是。物理学家需要它来识别无数不同的粒子探测器信号,市场研究人员需要它来识别消费者群体,气候科学家需要它来判断某个过程的起点和终点。与其他技术不同,我们的技术在不损害全球数据结构的情况下实现了降维,”共同作者DaniilCherniavskii说。
有许多方法可以降低数据维度,其中一些使用所谓的自动编码器。这些是创建数据的低维表示的神经网络。“问题在于,所使用的大多数技术,包括那些涉及自动编码器的技术,都是在本地运行的。它们关心数据点相对于相邻点的位置,但丢失了大规模结构,”Cherniavskii说。
“我们所做的是用一个新的附加损失函数来补充自动编码器。它的唯一目的是最小化初始数据集与其低维表示之间的拓扑差异。损失等于零时,可视化的“形状”得到保证与原来的相匹配。”
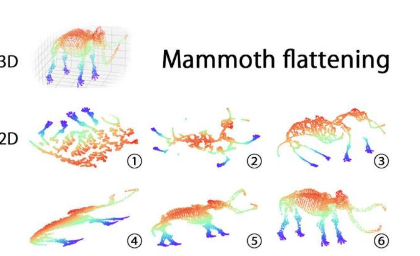
该团队使用多个指标测试了数据集拓扑结构的保留程度,这些指标捕获了一般数据点的相对位置(而不仅仅是那些紧邻的数据点)的保留程度。该测试包含不同性质的数据集,证实该团队的解决方案优于所有最流行的降维方法(见上图)。
“拓扑数据分析正在成为一种越来越流行的研究多维数据特性的工具。我们希望我们开发的方法和其他类似方法在不久的将来成为标准,”该研究的合著者SkoltechApplied的EvgenyBurnaev教授说。AI和AIRI说。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!